
The 3rd Summer Datathon on Linguistic Linked Open Data (SD-LLOD-19) will be held from May 12th to 17th, 2019 at Schloss Dagstuhl – Leibniz Center for Informatics, Wadern, Germany.
The SD-LLOD datathon has the main goal of giving people from industry and academia practical knowledge in the field of Linked Data and its application to natural language data and natural language annotations, from areas as diverse as knowledge engineering, lexicography, the language sciences, natural language processing and computational philology.
The final aim is to allow participants to develop their own use cases, i.e., migrate their own (or other’s) linguistic data and publish them as Linked Data on the Web. The datathon series is unique in its topic worldwide and continues a series of bi-annual datathons on Linguistic Linked Open Data organized since 2012.
The 2019 edition is organized in conjunction with and held before the 2nd International Conference on Language, Data and Knowledge (LDK-2019, May 20th-22th, Leipzig, Germany). The 2019 edition is supported by the Research Group "Linked Open Dictionaries (LiODi)" funded by the German Federal Ministry of Education and Research (BMBF), the H2020 Research and Innovation Action Prêt-à-LLOD. Ready-to-use Multilingual Linked Language Data for Knowledge Services across Sectors and the H2020 Research and Innovation Action ELEXIS. European Lexicographic Infrastructure.
During the datathon, participants will:
During the datathon, seminars will be organised to cover topics such as:
With the objective of avoiding passive learning, the program of the summer datathon will contain three types of sessions:
Participants will be invited to propose a “miniproject” related to the topic and to bring to the datathon some dataset of linguistic data produced by their organizations in order to work on it during the hacking sessions and transform it into linked data. Participants who cannot provide their own linguistic dataset can join another’s miniproject or some of the ones proposed by the organisers. There will be an award to the best miniproject.
Participants should bring their own laptops to follow the hacking sessions, but they will be provided with digital copies of all the material used during the course and will have assistance for installing all the required software.

As Professor of Computer Science at Goethe University Frankfurt, Germany, I am heading the Applied Computational Linguistics (ACoLi) lab since 2013, and the research group "Linked Open Dictionaries (LiODi)" since 2015. My research focuses on semantic technologies, including computational semantics as well as the innovative application of Linked Data formalisms to problems and resources in NLP and Digital Humanities.
For further information, please visit my website

I am a lecturer above-the-bar at the Insight Centre for Data Analytics at the National University of Ireland Galway. I am currently working with Paul Buitelaar in the Unit for Natural Language Processing. My main research has focused around the development of linguistic linked open data and in particular the development of models for the representation of lexical resources, by means of the lemon and OntoLex models.
For further information, please visit my personal website

I am an assistant professor at the Department of Computer Science and Systems Engineering (University of Zaragoza, Spain). I develop my research activities at the Distributed Information Systems group, belonging to the Aragon Institute of Engineering Research (I3A). My main research interests are Semantic Web, Ontology Matching, Multilingual Web of Data, Query Interpretation, and Linguistic Linked Data.
For further information, please visit my personal website
Local organization is handled by the members of the Research Group “Linked Open Dictionaries (LiODi)”, funded by the German Federal Ministry for Education and Science (BMBF).


We welcome participants from anywhere in the world and coming from industry or academia. Some basic acquaintance with software development and Web technologies is recommended. Participants are expected to participate fully in the activities of the datathon until its conclusion.
Fees: All SD-LLOD activities, including lecturers, tutors, teaching materials and social activities are sponsored by supporting research projects. Participants only cover the expenses for their stay, which are handled directly with the venue, Schloss Dagstuhl. Participants should stay for the entire duration of the event.
Note that datathon participants are entitled to a reduced attendance fee to the 2nd Conference on Language, Data and Knowledge (LDK-2019), Leipzig, Germany, May 20-22, 2019, please see the LDK registration page for details.
Registration: Registration is now open. You can apply by sending an email to datathon@linguistic-lod.org. Please provide a short description of
Potential participants will make an application until April, 4 2019. You will receive the selection result at April, 12th 2019.
Participants are encouraged to contribute to the datathon with their own data, their own research and their own challenges. If you want to propose a topic for a mini-project in the datathon (e.g., a language resource to be converted into linked data, a LLOD dataset to be linked to other resources, a use case description that exploits the LLOD cloud, ...) or want to report on some recent research related to the topics of the datathon, you can write a short description of your ideas (less than 1000 words), to be sent to the organisers via email as part of the registration process by 4th April. Selected mini-project proposals and abstracts will be highlighted and presented during the event.
Registration opens: January, 18th 2019
Registration closes: April, 4th 2019
Notification: April, 12th 2019
Datathon: May, 12th to 17th 2019
Payment: onsite only, upon arrival, starting May, 12th 2019, 15:00 CEST

Gerard de Melo is an Assistant Professor at Rutgers University (NJ,
USA), where he heads the Deep Data Lab. Over the years, he has published
over 100 papers on natural language processing, AI, and Big Data
analytics, with Best Paper/Demo awards at WWW 2011, CIKM 2010, ICGL
2008, and the NAACL 2015 Workshop on Vector Space Modeling. Notable
research projects include Lexvo.org, FrameBase.org, the Universal
WordNet, and the Etymological WordNet. Prior to joining Rutgers, he was
a faculty member at Tsinghua University and a Post-Doctoral Research
Scholar at ICSI/UC Berkeley. He received his doctoral degree at the Max
Planck Institute for Informatics.
For further information, please consult his website

Dr. Richard Eckart de Castilho is a senior research at the Ubiquitous Knowledge
Processing Lab, TU Darmstadt. He is interested in architectures, tools and
infrastructures for the automatic and interactive analysis of text data.
Richard is presently building a next-generation text annotation platform as a PI in the
DFG-funded project INCEpTION, member of the CEDIFOR Digital Humanities Centre,
member of the Apache Software Foundation, as well as the maintainer of DKPro Core,
WebAnno, Apache uimaFIT and involved in various other open source projects related
to NLP.
For further information, please consult his website
 Christian Fäth
Christian FäthThe Summer Datathon on Linguistic Linked Open Data (SD-LLOD-19) will be held from May 12th to 17th, 2019 at Schloss Dagstuhl – Leibniz Center for Informatics, in Wadern, Germany. Schloss Dagstuhl is a prominent location for workshops and meetings in computer science situated in an idyllic rural environment near the French and Luxembourg borders, and easily reachable via the cities of Mainz, Saarbrücken or Trier, resp. the airports Frankfurt am Main (FRA), Frankfurt-Hahn (HHN), Saarbrücken (SCN) or Luxembourg (LUX). For details on getting there, please see the Schloss Dagstuhl arrival information.
 photo (c) L. Sieht, Wikipedia, CC-BY 3.0
photo (c) L. Sieht, Wikipedia, CC-BY 3.0
| Sun 12/5 | Mon 13/5 | Tue 14/5 | Wed 15/5 | Thu 16/5 | Fri 17/5 | |
|---|---|---|---|---|---|---|
| 07:30 - 08:45 | breakfast | breakfast | breakfast | breakfast | breakfast | |
| 09:00 - 09:30 | Welcome | Presentation of participant groups | Practical Session: Generating & Publishing Language Resources | Seminar: Metadata | Seminar: OntoLex extensions | |
| 09:30 - 10:00 | Introduction: Linguistic Linked Open Data | Invited Talk: Richard Eckart de Castilho | Practical Session: Metadata | Practical Session: OntoLex extensions | ||
| 10:00 - 10:30 | Datathon | |||||
| 10:30 - 11:00 | break | break | break | break | break | |
| 11:00 - 11:30 | Practical Session: Linguistic Linked Open Data | Seminar: OntoLex-lemon | Practical Session: Linking Datasets | Datathon | Feedback and Review Session | |
| 11:30 - 12:00 | ||||||
| 12:00 - 12:30 | lunch | lunch | lunch | lunch | lunch | |
| 12:30 - 13:00 | ||||||
| 13:00 - 13:30 | daily report (tutors only) | daily report (tutors only) | daily report (tutors only) | Datathon Presentations | ||
| 13:30 - 14:00 | Seminar: Ontologies | Seminar: Annotations & NLP | Datathon | Datathon | ||
| 14:00 - 14:30 | ||||||
| 14:30 - 15:00 | Practical Session: Ontologies | Practical Session: SPARQL & CoNLL-RDF | Invited Talk: Gerard de Melo | |||
| 15:00 - 15:30 | Arrival & Registration | |||||
| 15:30 - 16:00 | coffee break | coffee break | coffee break | coffee break | coffee break | |
| 16:00 - 16:30 | Installfest: Technical Setup (all participants) | Participant's minute madness | Datathon | Excursion (Trier) | Datathon | Conclusion & Awards |
| 16:30 - 17:00 | ||||||
| 17:00 - 17:30 | Group Formation & Project Selection | Departure: 17:00 | ||||
| 17:30 - 18:00 | ||||||
| 18:00 - 18:30 | Dinner & Icebreaking | Dinner | Dinner | Dinner | ||
| 18:30 - 19:00 | ||||||
| 19:00 - 19:30 | Icebreaking Session | Datathon | Excursion | Social Evening | ||
| 19:30 - 20:00 | Conference Dinner | |||||
| 20:00 - 20:30 |
By default, we meet in Lecture Room Saarbrücken (LH-Sb).
| acronym | name | building | lectures | practical session | datathon sessions | mini project (tutor) |
| LH-Sb | Lecture Hall Saarbrücken | new building | X | X | X | 6 (Sina) & 7 (Julia) |
| LH-Kl | Lecture Hall Kaiserslautern | old building | _ | X* | X | 1 (Thierry) |
| S006 | Cafeteria | old building | _ | X** | X*** | 3 (Andon) |
| S104 | S104 | old building | _ | _ | X | 4 (Bettina) |
| S003 | S003 | old building | _ | _ | X | 2 (Christian F.) |
| News | News Room / Wappensaal | old building | _ | _ | X | 8 (Alessandro) |
| Trier | Room Trier | old building | _ | _ | X | 5 (Max) |
|
* if necessary, t.b.a. in the session before (Mon-Thu), ** instead of LH-Kl, Friday (Fri) only, *** if occupied, please move to LH-Kl (Mon-Thu) |
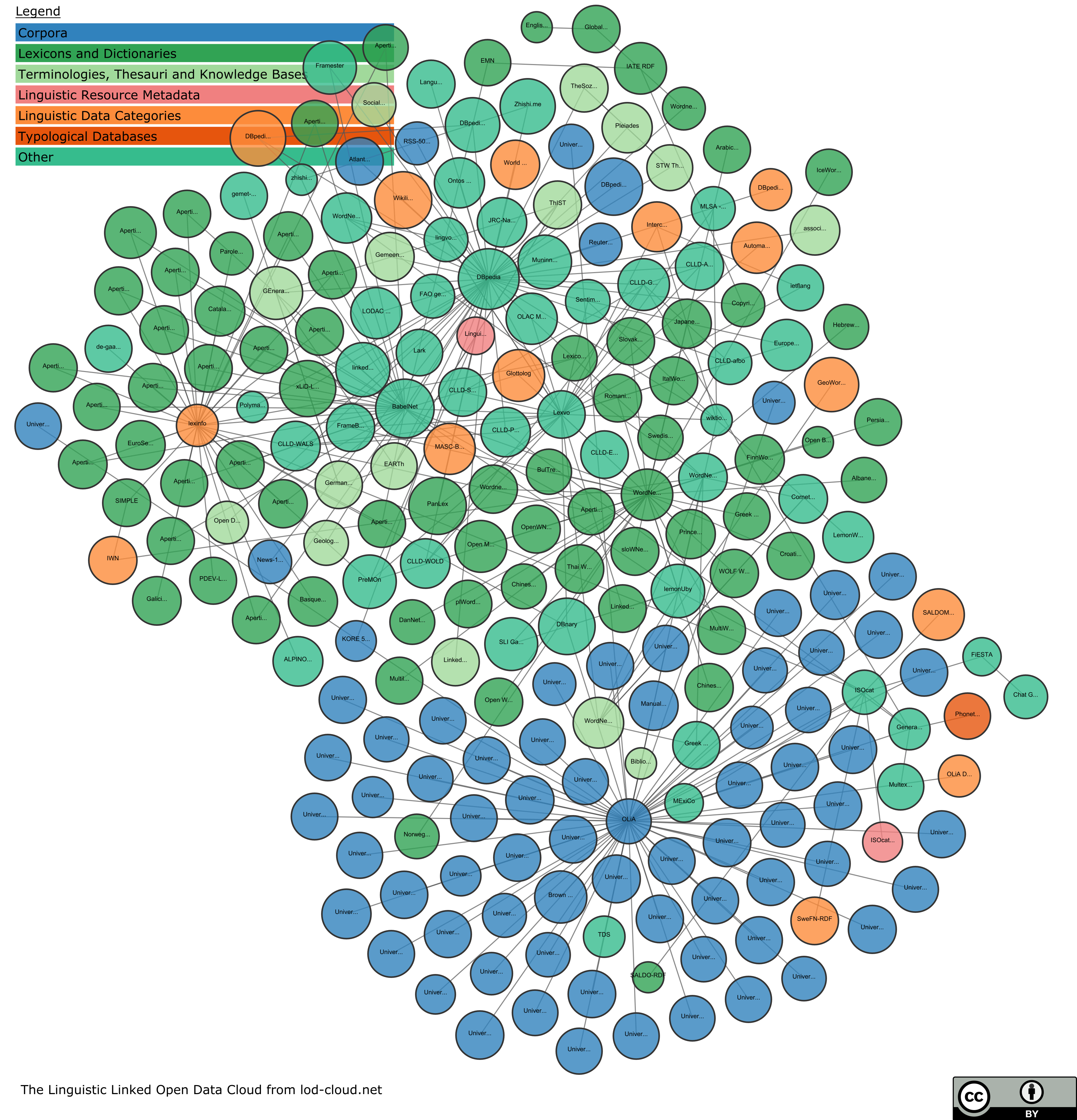
In natural language processing, linguistics, and neighboring fields, Linguistic Linked Open Data (LLOD) describes a method and an interdisciplinary community concerned with creating, sharing and (re-)using language resources in accordance with Linked Data principles. The Linguistic Linked Open Data cloud was conceived and is maintained by the Open Linguistics Working Group (OWLG) of Open Knowledge International, and has been a point of focal activity for several W3C community groups, research projects and infrastructure efforts since then.
To a large extent, LLOD development has been driven forward by international workshops and accompanying hackathons, as organized, for example, in the context of workshops on Multilingual Linked Open Data for Enterprises in 2012 and 2014 in Leipzig, Germany. Since 2015, these are organized in the form of bi-annual summer schools: The first Summer Datathon on Linguistic Linked Open Data (SD-LLOD’15) was held in June 2015 in Cercedilla, Madrid, Spain, as was the second Summer Datathon on Linguistic Linked Open Data (SD-LLOD’17) in July 2017. The 2019 edition is organized in conjunction with and held before the 2nd International Conference on Language, Data and Knowledge (LDK-2019, May 20th-22th, Leipzig, Germany).
Notable outcomes of earlier datathon editions include the first installment of the LLOD cloud and the LLOD cloud diagram (as a result of MLODE-2012), a large number of converted resources, and numerous scientific publications, and thesis projects that build on successful mini-projects, experiments or case studies conducted at or initiated during the previous SD-LLOD datathon.
 Sina Ahmadi
Sina Ahmadi Julia Bosque-Gil
Julia Bosque-Gil Max Ionov
Max Ionov Bettina Klimek
Bettina Klimek Andon Tchechmedjiev
Andon Tchechmedjiev Thierry Declerck
Thierry Declerck